Software · NLP with Deep Learning
Teaching LLMs to Teach
compute-efficient, pedagogically grounded math tutoring
Jan - March 2026
With two teammates, I worked on making large language models better, cheaper math tutors. Our paper, Adaptive Test-Time Compute for Pedagogically Grounded Reasoning in LLMs, started from a tension: the models that explain math well are usually too large and expensive for widespread educational use. We studied compute-efficient ways to raise the pedagogical quality of smaller open-source models.
We framed it as a teacher–student setup on the MATH dataset: a stronger model writes an explanation, and a weaker “student” model tries to solve the problem using it. That let us measure explanations by whether they actually help someone reach the right answer, not just whether the explanation itself is correct. It is a close cousin of knowledge distillation, where a stronger model’s outputs are used to improve a weaker one, except here we distill for explanation quality and downstream learning rather than raw accuracy.
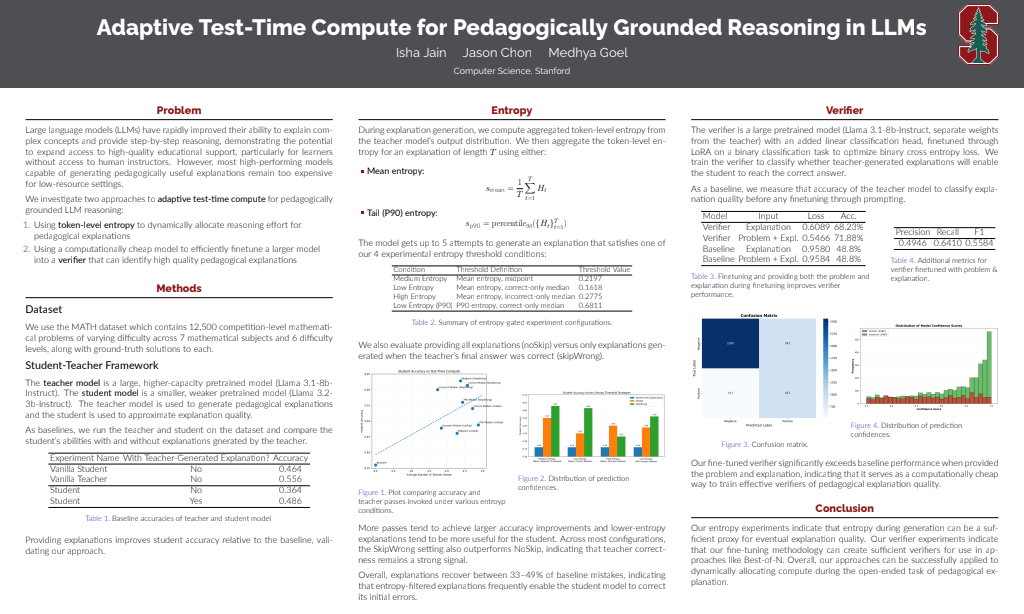
Our first approach used token-level entropy as a signal of the teacher’s uncertainty. Instead of spending a fixed compute budget on every problem, we regenerated an explanation only when the model looked unsure, allocating test-time compute where it was actually needed.
Teacher explanations significantly improved student accuracy over a no-explanation baseline, and the entropy-gated approach kept improving results while spending compute selectively rather than uniformly.
Our second approach finetuned a verifier: a model that predicts whether an explanation will lead to downstream student success, optimizing for pedagogical usefulness rather than just answer correctness. This avoided the complex, expensive training setups verifiers usually require.
The finetuned verifier reached 71.88% test accuracy, substantially outperforming a prompted baseline. Together, adaptive compute and pedagogically grounded verification point toward a way to get better explanations out of smaller, cheaper models, which is what it would take to make good tutoring genuinely accessible.